|
Today I got a notification from Twitter saying it was my 9 year anniversary. That's a long time and a lot has changed in the last 9 years. Looking back, my 2009 tweets include such things as "Waiting for the bus" and "Can't wait for finals to be over" -- a lot of my old tweets are pretty uneventful. There are a bunch of tweets regarding sporting events like the Olympics in 2016 and Super Bowl games and half-time shows. I've also got tweets that have "expired", i.e. tweets mentioning open job or internship postings with deadlines in the past. All of these old tweets are no longer relevant, are not representative of what I'm currently up to, and are now taking up a lot of space on my timeline.
So I've decided it's time to clean up my Twitter feed. A start to my spring cleaning - online edition. While writing this post I Googled "Deleting old tweets" to see what came up regarding the topic and I came across a post on Digital Minimalism (the author deletes 40,000 old tweets). It was a fitting post, as it covers many of the reasons why I'm cleaning up my Twitter feed. For me, it's important to keep the online version of myself up-to-date and to be deliberate about what I post. (Though on the latter point, Twitter is more than anything a stream of consciousness social media platform so deliberateness doesn't quite apply.) Ultimately, by getting rid of my old tweets I'll be maintaining a fresher Twitter timeline. While on that Google search (deleting old tweets), I also found there are apps you can use to make your old tweets self-destruct after a certain number of hours/days. I'm not going to go into any of those. For this endeavor, I'll be using the Twitter API, Stata, and cURL to delete my old posts. Before I get started on deleting old tweets, this is what my Twitter profile looks like. Notice the 5,493 tweets, this is going to go down by the end of this post. 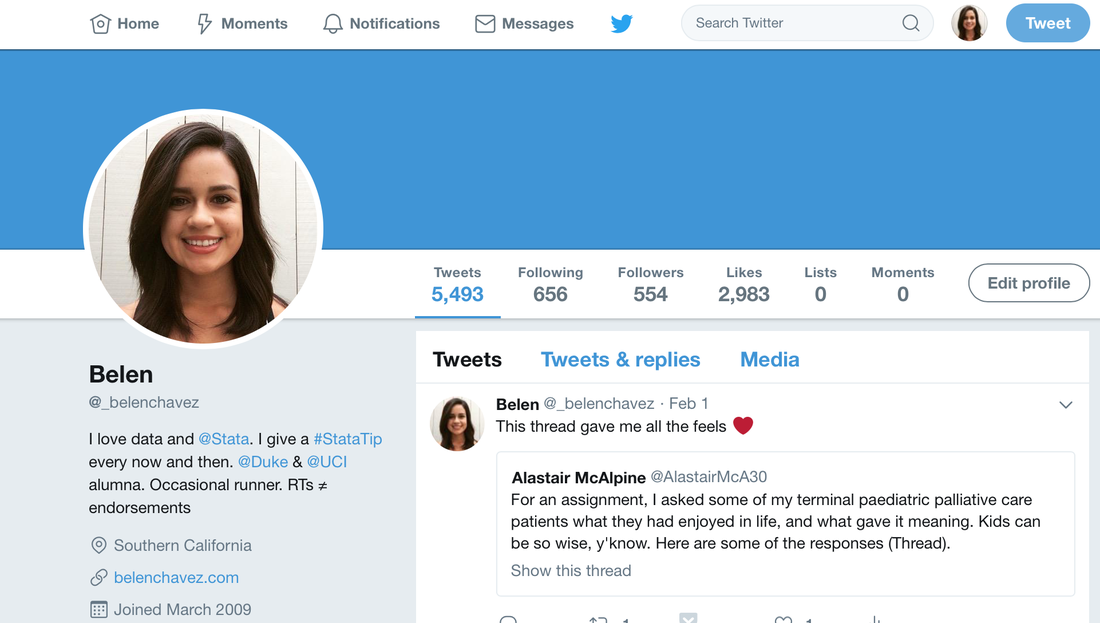
First things first, I downloaded my Twitter archive to get all of my tweets going back to the very first one - you can do this too by going to this link. Note that I didn't use the API since it can only return the most recent 3,200 tweets, for more information on the API check out Twitter's documentation.
The downloaded archive includes my Twitter export (all tweet activity) in CSV and JSON format. There's also an archive browser interface where I can search through all tweets and browse tweets by year and month (right side of the image below). Mine looks like this: 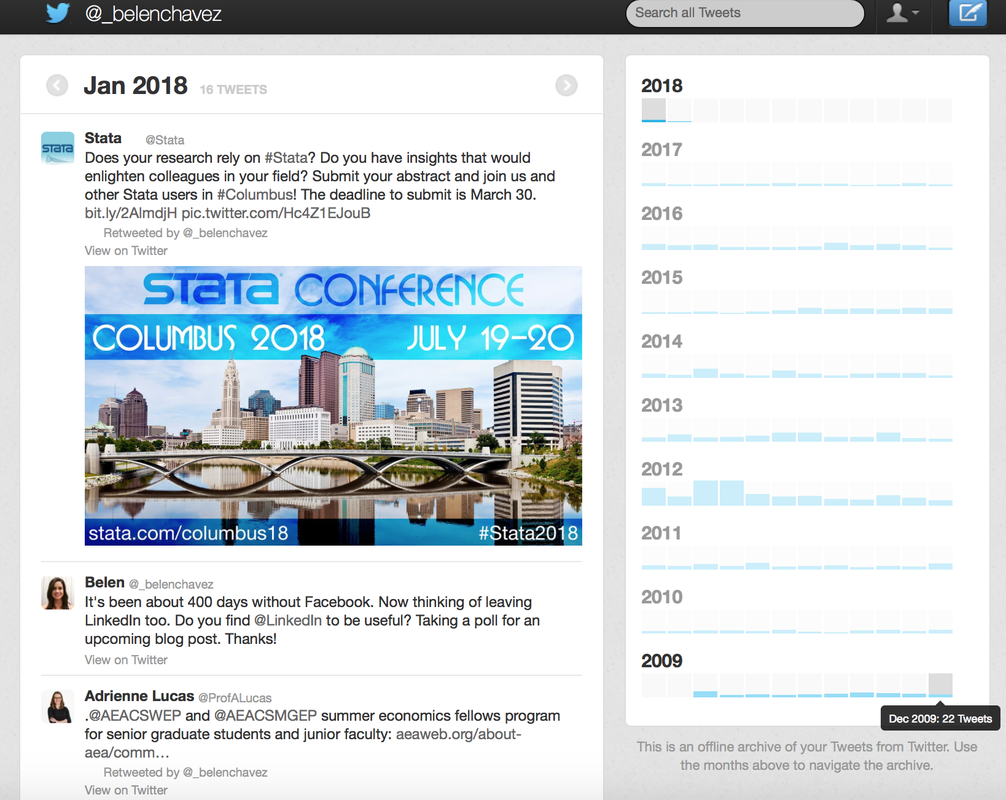
I imported my CSV file into Stata. Looking at my overall Twitter activity, I confirm that the bulk of my Twitter feed is indeed really old and outdated. About 80% of my tweets are from 2009-2014. I tweeted the most in 2012 and I tweeted the least last year. Here's a graph of my annual Twitter activity:
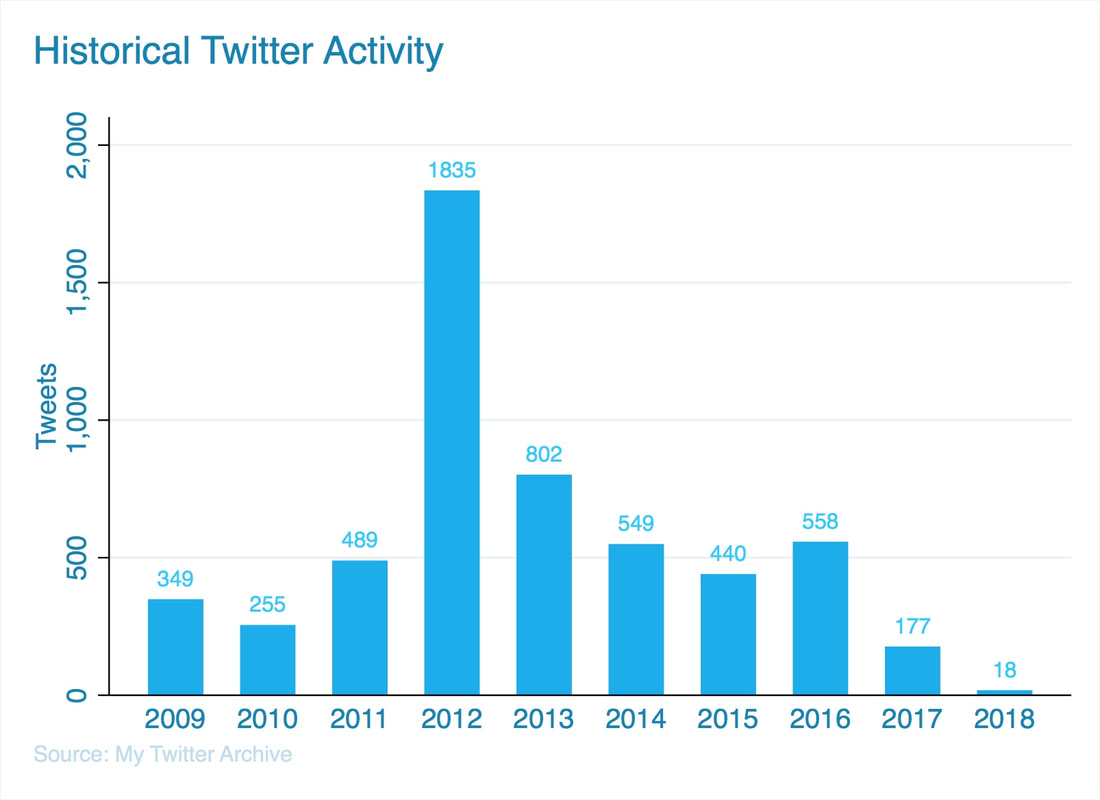
I made the bar graph using Stata and used Twitter's corresponding RGB colors. If you're interested in how I made it, here's the code for the graph:
graph bar totaltweets, over(year, label(labc("0 132 180"))) ///
ylab(, labc("0 132 180")) blabel(total, c("29 202 255")) ///
ytitl("Tweets", c("0 132 180")) bar(1, c("0 172 237"))///
tit("Historical Twitter Activity", c("0 132 180") span pos(11)) ///
note("Source: My Twitter Archive", c("192 222 237") span) ///
graphregion(color(white))
Now that I see what my activity looks like I can start flagging the tweets I want to delete. I'll be looping through the flagged tweets to delete them using the Twitter API. If you're not familiar with using Stata and the Twitter API together I suggest you first check out these two very informative blog posts by William Matsuoka: Stata and the Twitter API Part I and Part II, as I pretty much mirror his process.
First, I create a variable called delete which is equal to 1 if I want to delete that particular tweet (note: data is unique by tweet_id) Second, I decide what tweets I want to delete. My criteria is something like this:
In between the second and the third step, I also created another variable called always_keep that makes sure I keep Tweets with certain text in them like "Stata", "StataTip", "blogupdate", etc. This step is also not mentioned in the code below. As a short example, here's what my code looks for deleting tweets pre-2015:
clear all
set more off
version 15.1
/*Import the data*/
local twitter_dir "/Twitter API/Tweets/"
import delimited using "`twitter_dir'/twitter_archive/tweets.csv", clear ///
stringcols(1 2 3) bindquotes(strict)
replace timestamp = subinstr(timestamp, "+0000","",.)
gen date = dofc(clock(timestamp,"YMDhms"))
/*Create variable to mark tweets I want to get rid of*/
gen delete = 1 if year(date)<2015
levelsof tweet_id if delete ==1, local(mlist) clean
/*See http://www.wmatsuoka.com/stata/stata-and-the-twitter-api-part-ii
for what's included in this following .do file */
qui do "`twitter_dir'/0-TWITTER-PROGRAMS.do"
* For Timestamp (oauth_timestamp) in GMT
/*Note: Will uses a plugin for this portion. I shelled out date program on my Mac */
tempfile f1
! date +%s > `f1'
mata: st_local("ts", cat("`f1'"))
/*Pass the timestamp and tweet_ids as arguments in the following loop*/
foreach tweetid in `mlist'{
do 99_Delete_Tweets.do "`tweetid'" "`ts'"
}
The deletion of those pre-2015 tweets took my computer about 90 minutes to complete -- a rate of 40 tweets deleted per minute. The 99_Delete_Tweets.do file referenced above follows a very similar format to the one Will outlines in his blog post, except that instead of writing a tweet, we're removing it. For more information on deleting statuses see: Twitter's API Documentation. That do file looks a little something like this (note: I removed my personal API access information)
*99_Delete_Tweets.do:
*****************************************************************************
* Twitter API Access Keys
*****************************************************************************
* Consumer Key (oauth_consumer_key)
local cons_key = ""
* Consumer Secret
local cons_sec = ""
* Access Token
local accs_tok = ""
* Access Secret
local accs_sec = ""
* Signing Key
local s_key = "`cons_sec'&`accs_sec'"
* Nonce (oauth_nonce)
mata: st_local("nonce", gen_nonce_32())
* Signature method (oauth_signature_method)
local sig_meth = "HMAC-SHA1"
*****************************************************************************
*Delete tweets
*****************************************************************************
local del_id = "`1'"
local ts = "`2'"
* BASE URL
local b_url = "https://api.twitter.com/1.1/statuses/destroy/`del_id'.json"
* Signature
mata: st_local("pe", percentencode("`b_url'"))
local sig = "oauth_consumer_key=`cons_key'&oauth_nonce=`nonce'&oauth_signature_method=HMAC-SHA1&oauth_timestamp=`ts'&oauth_token=`accs_tok'&oauth_version=1.0"
mata: st_local("pe_sig", percentencode("`sig'"))
local sig_base = "POST&`pe'&"
mata: x=sha1toascii(hmac_sha1("`s_key'", "`sig_base'`pe_sig'"))
mata: st_local("sig", percentencode(encode64(x)))
!curl -k --request "POST" "`b_url'" --header "Authorization: OAuth oauth_consumer_key="`cons_key'", oauth_nonce="`nonce'", oauth_signature="`sig'", oauth_signature_method="HMAC-SHA1", oauth_timestamp="`ts'", oauth_token="`accs_tok'", oauth_version="1.0"" --verbose
Having perused the remaining Tweets in my archive, I ended up deciding to discard tweets older than 90 days with the exception of those that I flagged as always_keep.
After all this, my Twitter timeline now consists of 210* tweets. So I got rid of 96% of my tweets. I imported my current Twitter timeline into Stata using twitter2stata, twitter2stata tweets _belenchavez, clear
and created a visualization of my most commonly tweeted words using a word cloud. My new Twitter timeline is now up-to-date and fresher than before.

How many Stata's can you count?
Happy Anniversary, Twitter!
*Note: For as long as I can recall, I've had a discrepancy of 17 tweets on my timeline. So if you were to import my Twitter feed you'd get 193 tweets instead of the 210 that it shows me having on my Twitter profile. When users bulk delete their data there are 17 left over. It happens to a lot of people. The only recommendation I could find is to contact support.twitter.com.
0 Comments
Recently, I assigned a GIS problem set to my students and had them geocode addresses to obtain latitude and longitude coordinates using mqgeocode in Stata. The reason I had them use mqgeocode and not geocode3 is because the latter is no longer available through ssc. Does anybody know why? Somebody please tell me. What's the difference between the two? One difference between the two is that mqgeocode uses MapQuest API and geocode3 uses Google Geocoding API.
Anyway, after my students downloaded mqgeocode, I received several emails from students letting me know that they could not obtain coordinates no matter what format the addresses were in. See below: 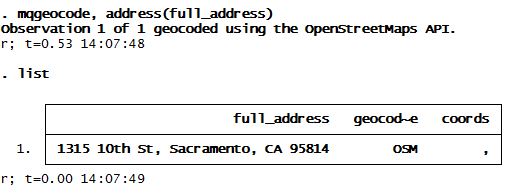
What? No coords? Why not? With the help of the nice people over at www.wmatsuoka.com we dug a little deeper and saw that the API key in that program had probably hit its limit which is why it wasn't returning any coordinates.
A quick fix for that is to replace the two lines in that ado file with your personal API key. How do you get a MapQuest API key? Just sign up for one here. It's pretty quick and fairly easy. Then look for the lines "local osm_url1 =" and put in your own API key. I put in my API key in a local called `apikey' which was passed on to the following lines in that program. The following two lines correspond to lines 47 and 141 of the mqgeocode.ado file, respectively:
local osm_url1 = "http://open.mapquestapi.com/geocoding/v1/reverse?key=`apikey'&location="
local osm_url1 = "http://open.mapquestapi.com/geocoding/v1/address?key=`apikey'&location="
I renamed that ado file and program as mqgeo2 and quickly got to geocoding: 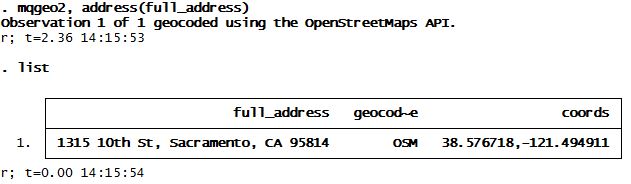
And voilà! We now have latitude and longitude coordinates for our address which happens to be the California State Capitol building.
Ta da! This is what (old) MapQuest looks like (I miss Google already) 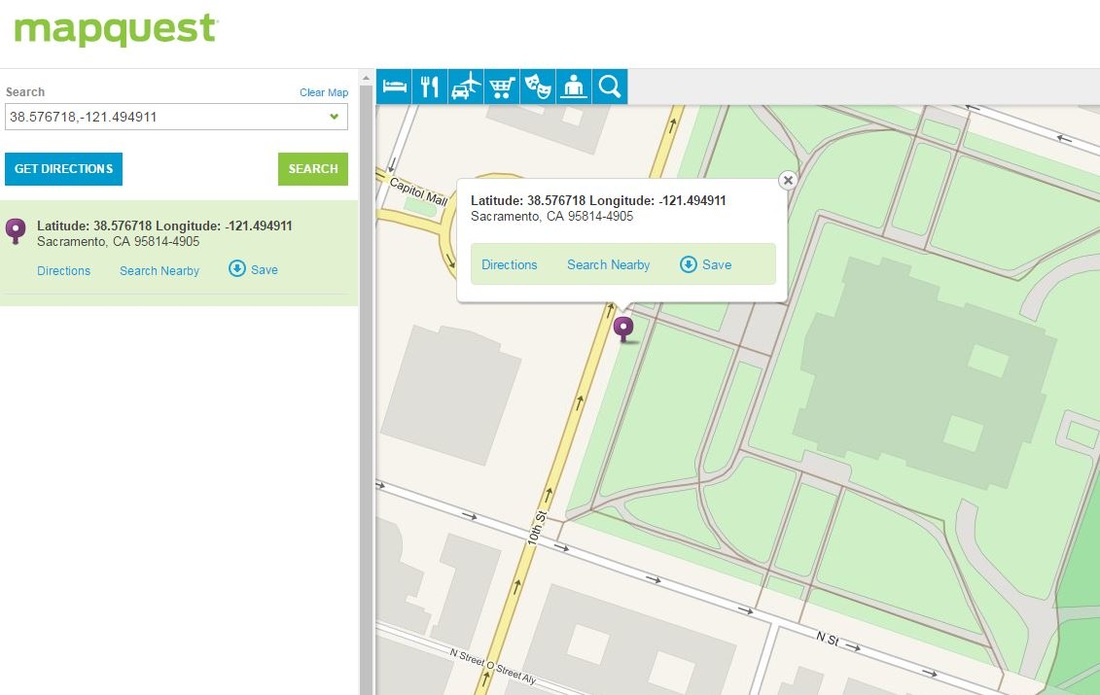
This is a continuation of the work I did in part 1 using BreweryDB data. I've cleaned most files with brewery and beer information (only 44 files could not be parsed using insheetjson in Stata, but I'm working on those separately, they will be included in my analysis at a later time). For now, this analysis only includes files which I was able to parse.
So, who makes beer? Breweries. What styles are there? Well let me tell you. There are the following styles in BreweryDB. Under each style there are up to 170 beer categories (or sub-styles?) like the ones I described in Part 1.
Looks like the unique count of breweries with North American Origin Ales style surpasses all other counts with close to 3,500 in this (somewhat complete) sample. With the explosion of micro-breweries, and all kinds of people getting into beer, I guess I'm not too surprised. So, what types of beers are contained within this style? I've summarized them here. The top 50% of the North American Origin Ales are made up by the following styles: American-Style India Pale Ale (19%), American-Style Pale Ale (15%), American-Style Amber/Red Ale (11%) and the Imperial or Double India Pale Ale (9%). See table below.
Interesting. To be honest, I don't like IPAs, pale ales, or IIPAs. They're just too hoppy for my taste. Pass me a Belgian instead. On that note, here are the counts of breweries who make Belgian & French Origin Ales.
A lot lower than the North American Origin Ales, but with the IPAs growing out of control (or so it feels like they are here in San Diego), I guess that makes sense. Plus, while there are fewer breweries that make Belgian and French Ales these types of beer seem to have been around longer. For example, the earliest established brewery with Belgian and French Ales is in 1121 by Leffe versus 1471 for the earliest North American Ale which interestingly enough corresponds to the beer style "Golden or a Blonde Ale" made by none other than a Belgian Brewery: Hetanker. Aren't Belgian breweries just the best?
I've mapped the breweries that make Belgian and French Origin Ales below that are located in California, Texas, North Carolina, New York, and D.C. Why these states? These are the states where most of my site's visitors are from :)
Like I said in the first post, there's a lot of data and I've only shown you a little bit of it! Look forward to more posts that use additional variables that I haven't even mentioned and maybe cooler maps. Cheers!
A few days ago, I attended the San Diego Economic Roundtable at the University of San Diego which included a panel of experts discussing the economic outlook for San Diego County. My favorite speakers were Marc Martin, VP of Beer, from Karl Strauss and Navrina Singh, Director Product Management, from Qualcomm. Singh had a lot to say about data, technology, innovation and start ups in San Diego County. Did you know that there are 27 coworking spaces, accelerators, and incubators in San Diego? I sure didn't. Martin's discussion of beer, all the data he showed, along with some cool maps, sparked this blog post which has been a long time coming. In case you don't know, I'm quite the craft beer enthusiast! Allow me to nerd out as two of my favorite things come together: data and craft beer.
Martin's talk focused on the growing number of microbreweries and craft beer data. Here are some cool facts I came away with from his presentation that are worth mentioning again:
On to my blog post: While searching for beer data for this blog post, I stumbled across a gold mine: BreweryDB.com. I got access to their data using API. In the last few days, I've looped through over 750 requests using Stata's shell command and Will's helpful post on Stata & cURL. In the table below I've detailed the number of beers (listed as results) under each style ID in BreweryDB's database. There are a total of 48,841 beers as of January 17, 2016. When filtering for the word "Belgian" in the style name, I got a total of 5,883 beers. Can you guess what my favorite type of beer is? :) I made the table below using Google Charts API table visualization. There are a total of 170 beer style IDs under BreweryDB and I've summed up the number of beers under each style. You can sort by ID, Beer Style or Results by clicking on whichever column title you'd like.
Disclaimer: This product uses the BreweryDB API but is not endorsed or certified by PintLabs.
Seeing as BreweryDB's data is extensive and I'm oh-so excited to share with you some of my findings, I've decided to make a series of blog posts about this. This is why this is part 1. This is only the tip of the iceberg, my friends, and I'm not sure how big of an iceberg I'll be uncovering, but stay tuned for more.
|
